那大神教這門課一定有他的深意
我們要好好依止
所以做好前行之後就開始好好的學吧
相信一定可以有所幫助!
森林顧名思義 ,是有一堆樹
那這些樹又是什麼呢?
就是我們常見的決策樹(decesion tree)
在介紹決策樹之前,老師先用2元分割讓我們入門理解決策樹的原理
import seaborn as sns
fig,axs = plt.subplots(1,2, figsize=(11,5))
sns.barplot(data=df, y=dep, x="Sex", ax=axs[0]).set(title="Survival rate")
sns.countplot(data=df, x="Sex", ax=axs[1]).set(title="Histogram");
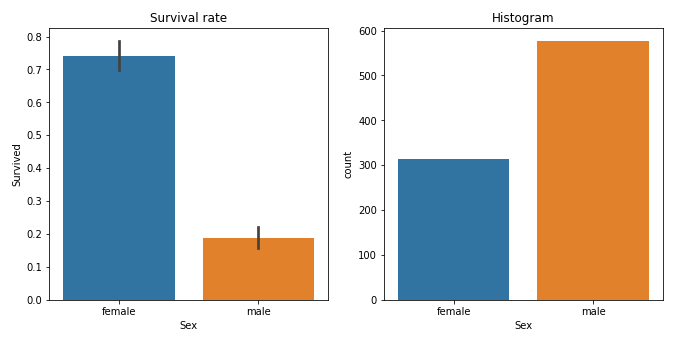
在這邊很明顯的可以看到,女性存活比例非常高!
所以我們如果創建一個超級簡單的model ,這個model 就只用性別這個單一特徵來區分存活與否
我們看看會發生什麼事
from numpy import random
from sklearn.model_selection import train_test_split
random.seed(42)
trn_df,val_df = train_test_split(df, test_size=0.25) # 切75%訓練集,25%驗證集
trn_df[cats] = trn_df[cats].apply(lambda x: x.cat.codes) #cat 就是category,類別的縮寫,不是貓XDD
#所以這邊是把類別數據做編碼,就像之前學的
one-hot coding 也是一種類別編碼
val_df[cats] = val_df[cats].apply(lambda x: x.cat.codes)
這段程式碼是將數據集分為訓練集和驗證集,並將類別的特徵做數字編碼,以便後續的模型訓練和測試。
def xs_y(df):
xs = df[cats+conts].copy()
return xs,df[dep] if dep in df else None
trn_xs,trn_y = xs_y(trn_df)
val_xs,val_y = xs_y(val_df)
這邊就是幫我們把訓練跟pred 拆開來,如果dataframe 中有"dep"這個欄位,就把這個設定為y ,然後return。
由於之前我們已經做過數據處理,所以可以直接用。
如果是新開的notebook,就要再做一次前面幾天的數據預處理。
我們可以看一下我們的pred 長什麼樣子
然後上面的sex==0 就是我們的model
對你沒看錯,就是這麼樣一行。
那有了model ,當然要看看我們這樣做的結果好不好。
接下來要設定loss function。
這邊採用mean absolute error 來評量
from sklearn.metrics import mean_absolute_error
mean_absolute_error(val_y, preds)
val_y 就是實際的存活與否
preds 就是剛才預測的結果(sex==0 就代表存活)
這樣跟實際誤差多少呢?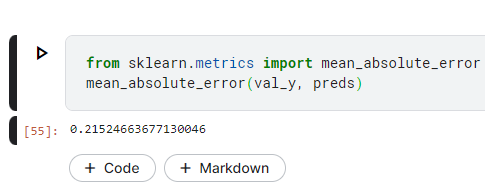
該如何改進我們的單點預測器呢?
在這邊我們將試著開始建立決策樹。
決策樹的定義我們可以直接google ,以下主要是看看怎麼實作。
針對每個性別群體,創建一個額外的二元分割。也就是說
對於女性找到最適合的單一分割
對於男性也找到最適合的單一分割
cols.remove("Sex")
ismale = trn_df.Sex==1
males,females = trn_df[ismale],trn_df[~ismale]
以下這個程式不用看懂,因為他其實有點長
牽涉到一堆知識,主要知道他在幫我們找欄位的分割點就好
也就是說,如果是年齡這個欄位,我們怎麼樣一分為二?
因為我們都是想建立很多個 是/否 的樹
但是要建立這個是/否的時候,就是在建立分割
這個分割要怎麼分才算好呢?
這就是下面這個function在幫我們做的事,他可以告訴我們要怎樣去分成2個子集
def min_col(df, nm):
col,y = df[nm],df[dep]
unq = col.dropna().unique()
scores = np.array([score(col, y, o) for o in unq if not np.isnan(o)])
idx = scores.argmin()
return unq[idx],scores[idx]
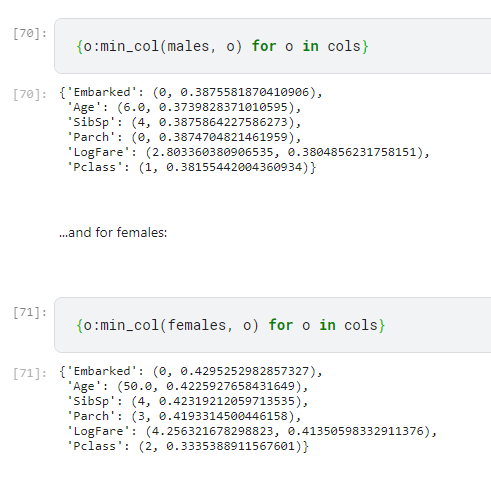
所以我們可以看到男生的最佳分割是 Age<=6
女生則是 Pclass<=2
所以我們在增加這些規則時,我們就是在建立決策樹
因為我們一開始會把群體分為 男?女?
如果是男,則再分他的Age<=6?是的話一群,否的話另一群
如果是女,則就問Pclass 是否<=2
所以見下面的程式
import graphviz
from sklearn.tree import DecisionTreeClassifier, export_graphviz
m = DecisionTreeClassifier(max_leaf_nodes=4).fit(trn_xs, trn_y);
def draw_tree(t, df, size=10, ratio=0.6, precision=2, **kwargs):
s=export_graphviz(t, out_file=None, feature_names=df.columns, filled=True, rounded=True,
special_characters=True, rotate=False, precision=precision, **kwargs)
return graphviz.Source(re.sub('Tree {', f'Tree {{ size={size}; ratio={ratio}', s))
draw_tree(m, trn_xs, size=10)
可以看到畫出來的圖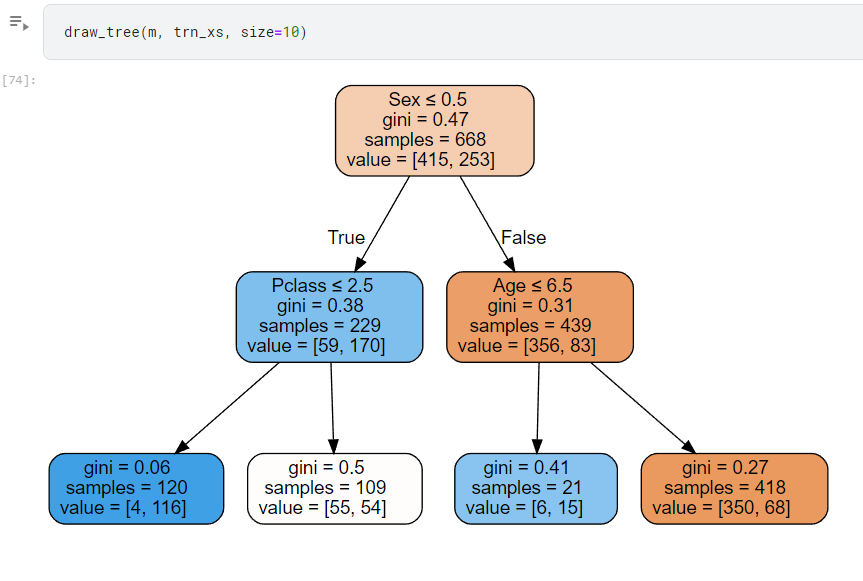
那看到這沒什麼感覺,我們得知道這個樹有比剛才有用
剛剛光靠性別,就可以得到0.21這個平均誤差
現在又多加了2條rule ,是否會更好呢?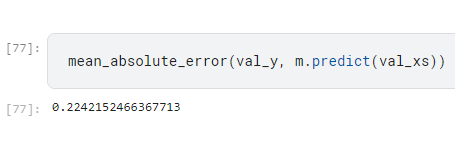
好可以看到結果更爛了XDDDD
在這邊作者解釋可能是因為只抽了200個樣本來做這件事,所以沒什麼意義
然後他把資料集擴大又增加更多規則下去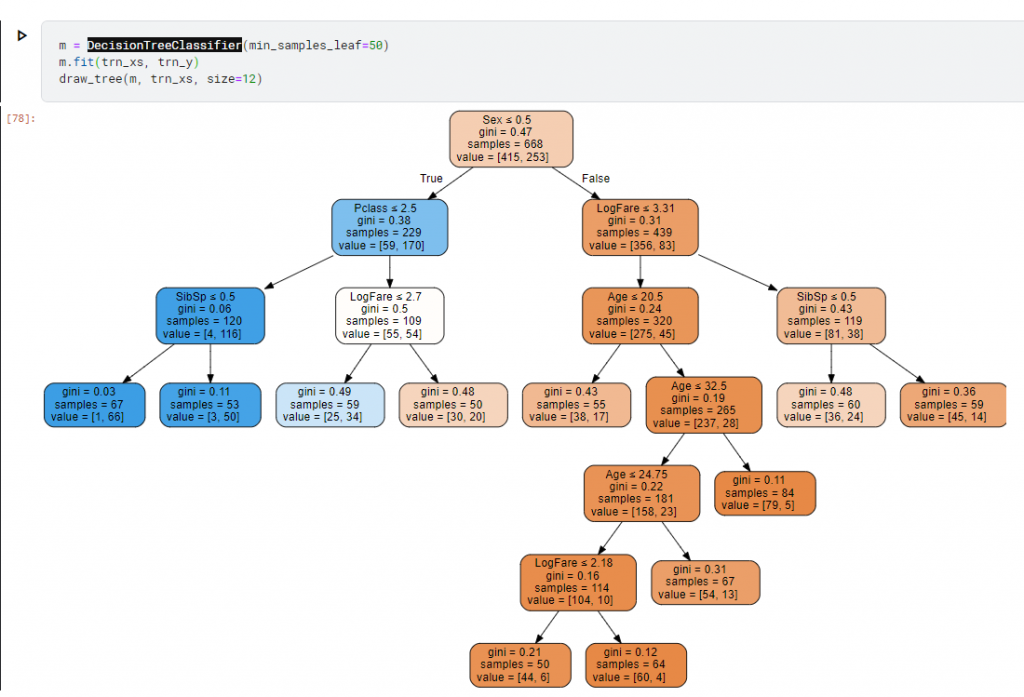
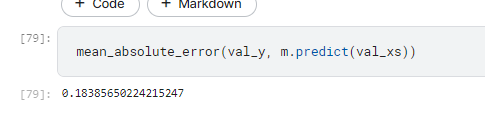
哦厚,變好一點了!
在這邊我們看到決策樹的作用!也看到決策樹的「高解釋性」這個在需要做解釋的時候就很有用了~
在這邊我們不用細究什麼是gini ,什麼是score
只要知道大概就好。如果要深究的話,就讀傳統的機器學習理論XD
講師說以他自己的狀況來說,隨機森林的使用頻率大概10% ,深度學習有90%
所以應該就是交互使用,以深度學習為主,隨機森林看情況使用
那怎麼使用,以及怎樣能幫助我們,就明天再說嘍。

